App-embeddable runner
Gives any app a local model runtime surface without making that app own daemon startup, status, or routing logic.
// LOCAL AI RUNTIME
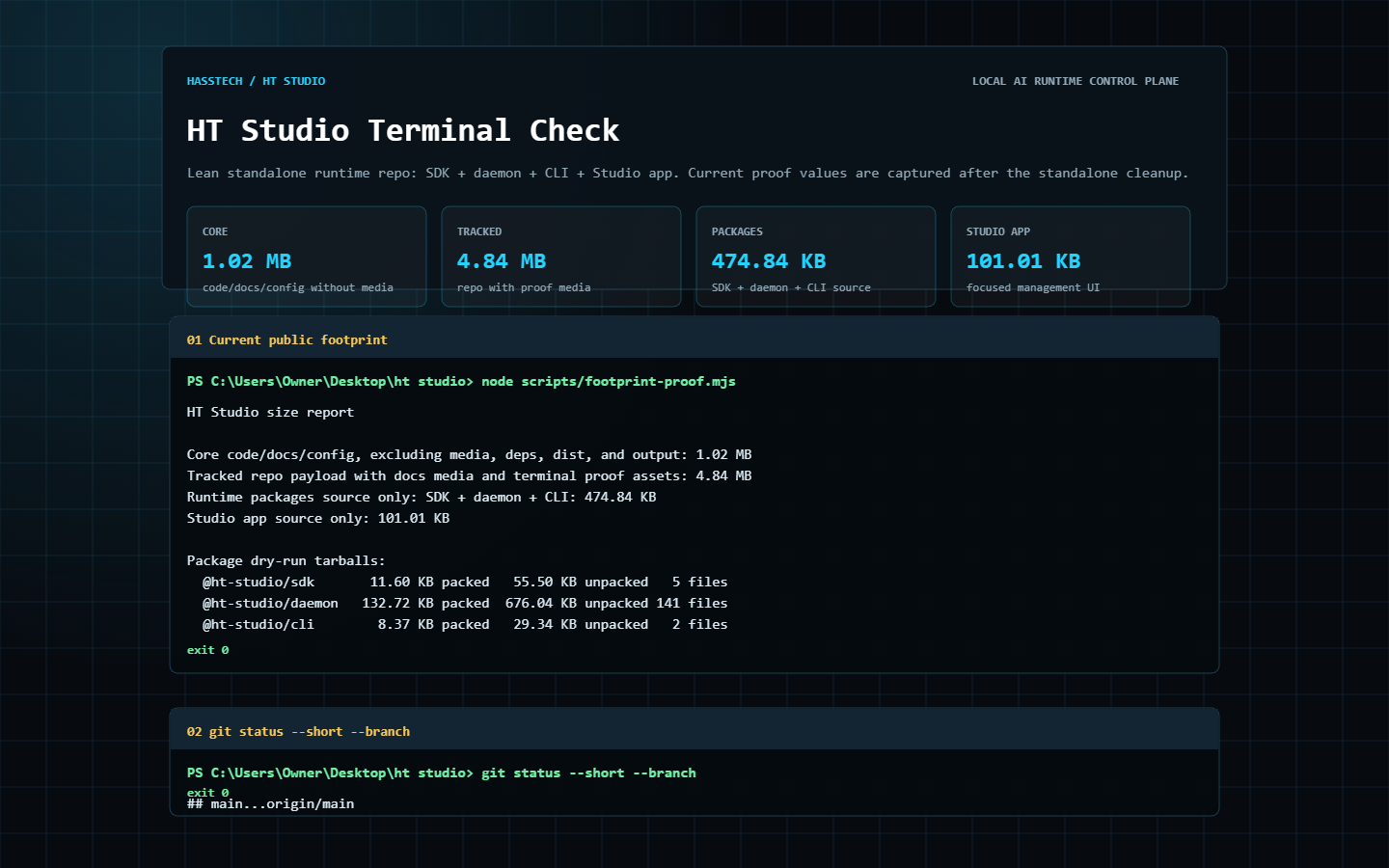
A 1.02 MB standalone local model runner for adding workstation AI to any app through one daemon, CLI, SDK, and OpenAI-compatible API.
Excluding media, deps, dist, and output
Repo payload with screenshots and video
SDK + daemon + CLI
Focused management UI
HT Studio is the standalone runtime side of the HassTech local AI stack. It is not a model marketplace page and it is not a bundled model-weight package. It is a small control plane that lets apps start, verify, and reuse local model execution through one local interface.
Looking for model discovery? Open HT LLM Marketplace ->Gives any app a local model runtime surface without making that app own daemon startup, status, or routing logic.
Finds installed local model artifacts and runtime folders without forcing every product to implement discovery itself.
Keeps the workstation control plane local by default through daemon, CLI, SDK, and API surfaces.
Verifies daemon health, endpoint coverage, runtime state, GPU visibility, and installed artifacts before routing.
Lets apps point at familiar local chat, responses, and model routes without a cloud model handoff.
The local runtime path does not need to send prompts to a hosted model API.
Small source size keeps the control plane auditable. The heavy parts of local AI are the models, local dependencies, and generated build/output folders on the user machine. The repo stays honest about that boundary.
| Scope | Size | Meaning |
|---|---|---|
| Core code/docs/config | 1.02 MB | Excluding media, deps, dist, and output |
| Tracked with proof media | 4.84 MB | Repo payload with screenshots and video |
| Runtime packages source | 474.84 KB | SDK + daemon + CLI |
| Studio app source | 101.01 KB | Focused management UI |
HT Studio discovers local runtime artifacts, verifies that the daemon and endpoints are ready, then exposes a familiar local API surface so a product, agent, dashboard, or desktop app can call local models without owning every runtime-specific detail.
// MARKETPLACE CONNECTION
HT Studio is the local runner. HT LLM Marketplace is the separate catalog and discovery surface for finding model options, comparing fit, and showing marketplace-specific proof before a model is handed to the runner.
View Marketplace PageUse HT LLM Marketplace to search, compare, and explain local model options before a runner needs them.
Pair catalog choices with compatibility notes, local readiness checks, and terminal proof for reviewers.
Hand selected models and runtime context back to HT Studio for daemon, CLI, SDK, and /v1 execution.
The proof media is captured from the repo after the standalone cleanup: size summary, smokes, CLI help, live daemon status, and readiness output.
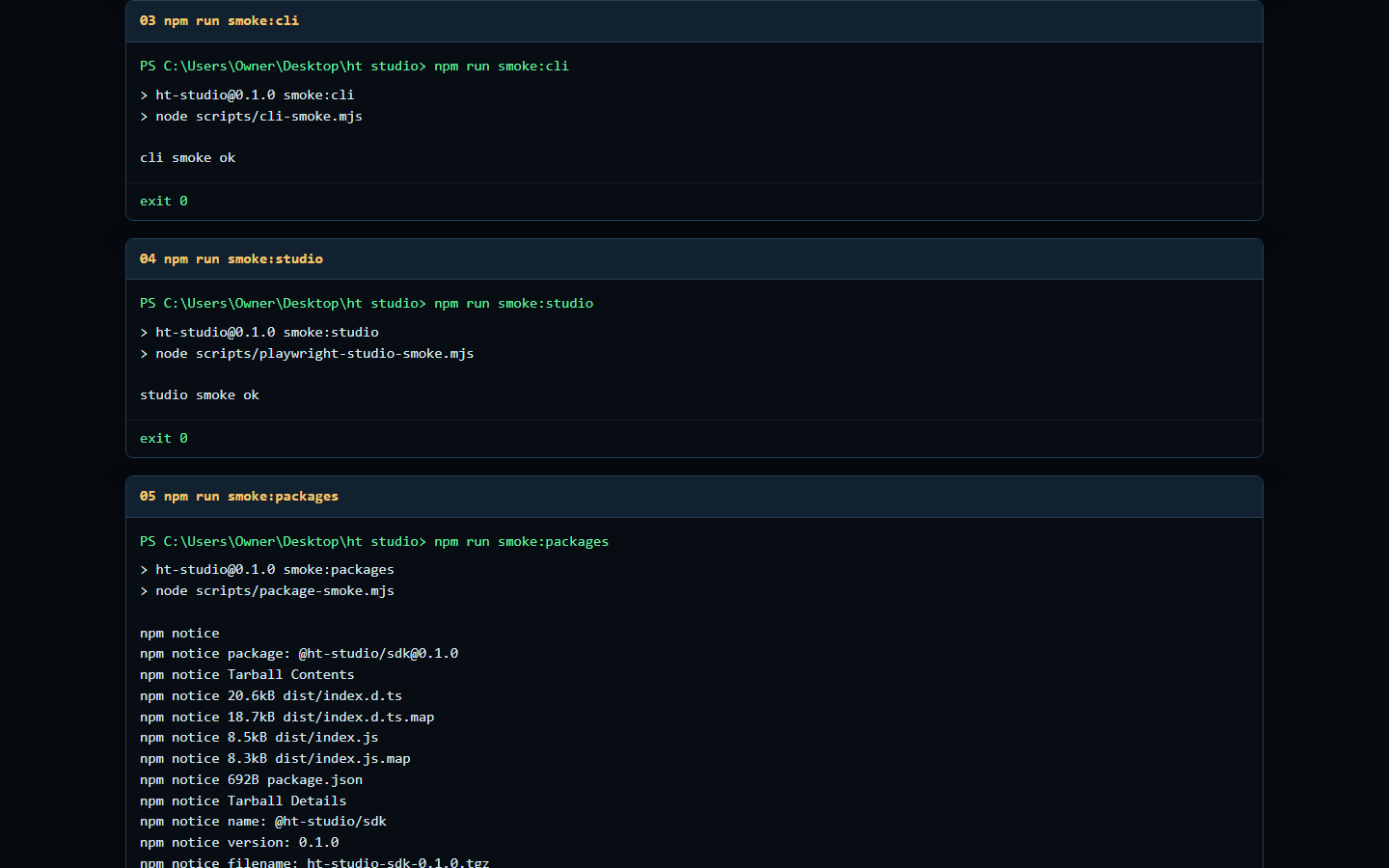
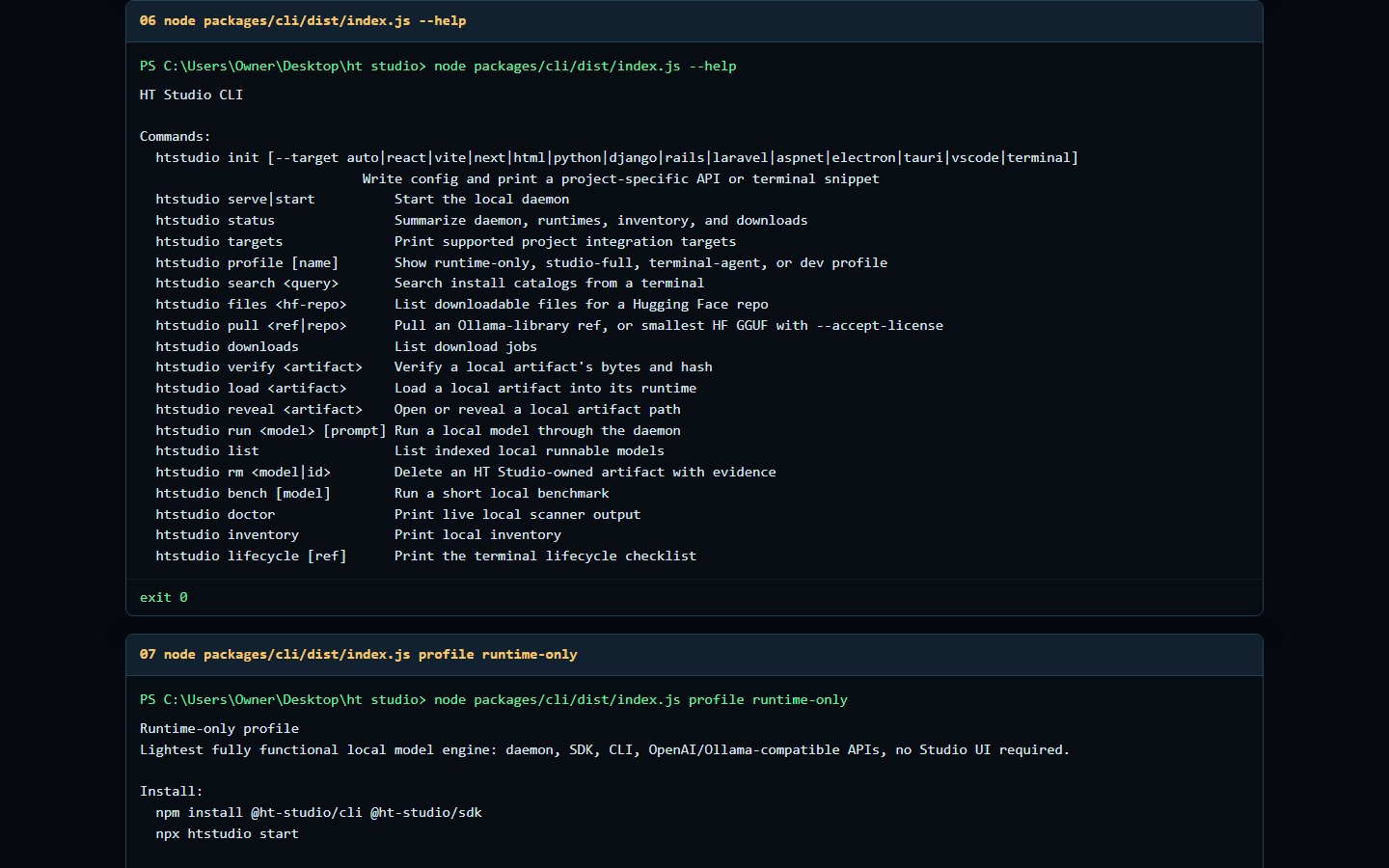
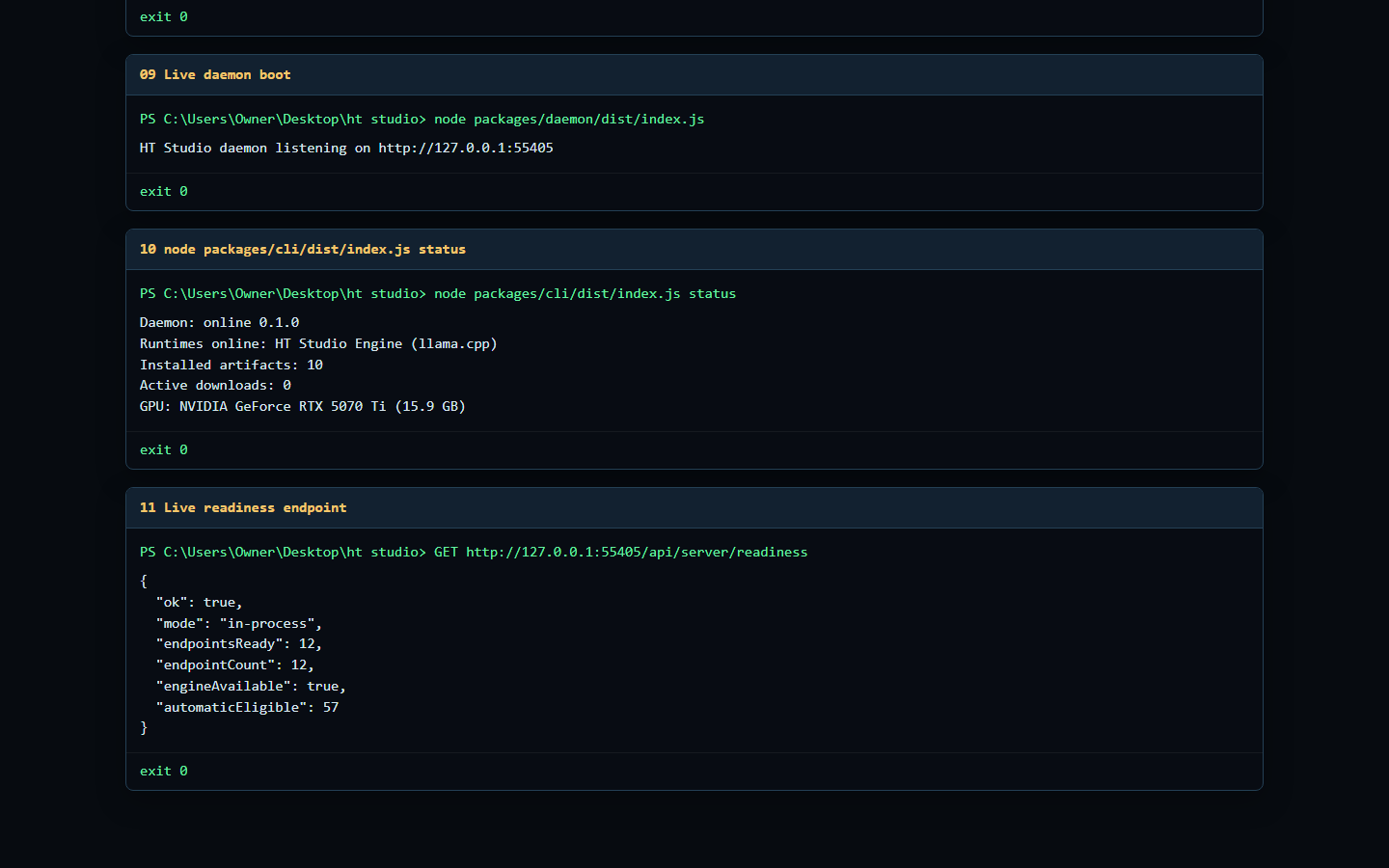
Use the daemon for local runtime orchestration, the CLI for terminal-first workflows, the SDK for typed app integration, and the OpenAI-compatible API for projects that already know how to speak /v1. HT Studio is the runner; HT LLM Marketplace is the separate catalog and discovery surface.